
java系统找不到指定文件怎么解决
237
2022-10-12
企业常用GFS分布式存储系统
GlusterFS简介
开源的分布式文件系统 由存储服务器,客户端以及NFS/Samba存储网关组成 无元数据服务器 GlusterFS特点 扩展性和共性能 高可用 全局统一命名空间 弹性卷管理 基于标准协议
GlusterFS概述
Brick存储节点 Volume卷 fuse内核模块,用户端的交互性模块 vfs虚拟 Glusterd服务
来理解一下这张图:
上面一层虚拟化管理层,想当于一个应用。缓存,读写头,条带卷,代理想当于API接口 中间rdma传输 相当于一个驱动 下面一层真实的设备 相 当于一个硬件
clusterFS工作流程
弹性HASH算法 通过HASH算法的到一个32位的整数 划分位N个连续的子空间,每个空间对应一个Brick 弹性HASH算法的优点 保证 数据平均分布在每一个Brick中 解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈 通过HASH算法的到一个32位算法,去算去选择,因为你的每一个节点都存储一部分数据,你怎么去识别排序,通过算法。
四个Brick节点的GlusterFS卷,平均分配232次方的区间的范围空间
通过hash算法去找到对应的brick节点的存储空间,去分配数据存储,去调用每一个节点数据
clusterfs的卷类型
分布式卷 复制卷 分布式条带卷 分布式复制卷 条带复制卷 分布式条带复制卷
分布式卷
没有对文件进行分块处理 通过扩展文件属性保存HASH值 支持的底层文件系统有ext3,ext4,ZFS,XFS等 **分布式卷具有如下特点** 文件分布在不同的服务器,不具备冗余性 更容易和廉价地扩展卷的大小 单点故障会造成数据丢失 依赖底层的数据保护 我们有办法解决,因为它存的文件都是完整的,我们可以做个镜像卷,做个备份
条带卷
根据偏移量将文件分成N块(N个条带节点),轮询的存储在每个Brickserver节点 存储大文件时,性能尤为突出,不具备冗余性,类似Raid0 **特点** 数据被分割成更小块分布到块服务器群中的不同条带区 分布减少负载且更小的文件加速了存取的速度 没有数据冗余
复制卷
同一个文件保存一份或多分副本 复制模式因为保存副本,所以磁盘利用率较低 多个节点的存储空间不一致,那么将按照木桶效应取最低节点的容量作为该卷的总容量 **特点** 卷中所有的服务器均保存一个完整的副本 卷的副本数量可以有客户创建的时候决定 至少由两个块服务器或更多服务器 具备冗余性
分布式条带卷
兼顾分布式卷和条带卷的功能 主要用于大文件访问处理 至少最少需要4台服务器
分布式复制卷
兼顾分布式卷和复制卷的共呢 用于需要冗余的情况下 ··· ## GFS分布式文件系统集群项目 ## 群集环境 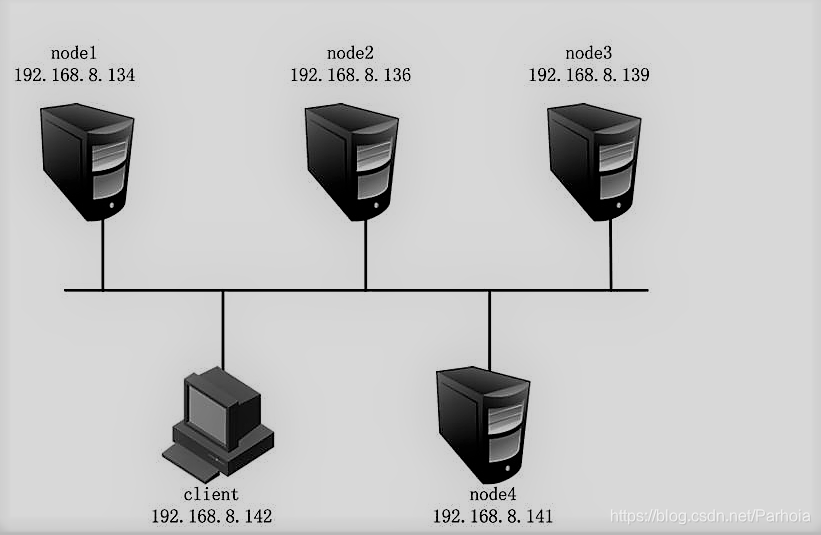 ## 卷类型 | 卷名称 | 卷类型 | 空间大小 | Brick| |--|--|--|--| |dis-volume | 分布式卷 |40G | node1(/b1)、node2(/b1) | |stripe-volume | 条带卷 | 40G|node1(/c1)、node2(/c1) | | rep-volume | 复制卷 |20G |node3(/b1)、node4(/b1) | | dis-stripe | 分布式条带卷 | 40G| node1(/d1)、node2(/d1)、node3(/d1)、node4(/d1) | | dis-rep | 分布式复制卷 | 20G| node1(/e1)、node2(/e1)、node3(/e1)、node4(/e1) | ## 实验准备 #### 1、为四台服务器服务器每台添加4个磁盘 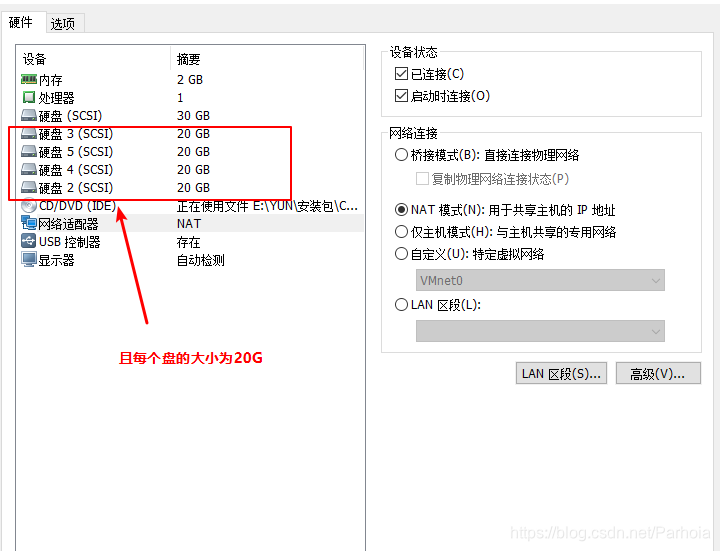 #### 2、修改服务器的名称 分别修改为node1、node2、node3、node4 ```sql [root@localhost ~]#hostnamectl set-hostname node1 [root@localhost ~]# su
3、将四台服务器上的磁盘格式化,并挂载
在这里我们使用脚本执行挂载
#进入opt目录 [root@node1 ~]# cd /opt #磁盘格式化、挂载脚本 [root@node1 opt]# vim a.sh #! /bin/bash echo "the disks exist list:" fdisk -l |grep '磁盘 /dev/sd[a-z]' echo "==================================================" PS3="chose which disk you want to create:" select VAR in `ls /dev/sd*|grep -o 'sd[b-z]'|uniq` quit do case $VAR in sda) fdisk -l /dev/sda break ;; sd[b-z]) #create partitions echo "n p w" | fdisk /dev/$VAR #make filesystem mkfs.xfs -i size=512 /dev/${VAR}"1" &> /dev/null #mount the system mkdir -p /data/${VAR}"1" &> /dev/null echo -e "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0\n" >> /etc/fstab mount -a &> /dev/null break ;; quit) break;; *) echo "wrong disk,please check again";; esac done #给于脚本执行权限 [root@node1 opt]# chmod +x a.sh
将脚本通过scp推送到其他三台服务器上
scp a.sh root@192.168.45.134:/opt scp a.sh root@192.168.45.130:/opt scp a.sh root@192.168.45.136:/opt
在四台服务器上执行脚本,并完成
这个只是样本
[root@node1 opt]# ./a.sh the disks exist list: ================================================== 1) sdb 2) sdc 3) sdd 4) sde 5) quit chose which disk you want to create:1 //选择要格式化的盘 Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x37029e96. Command (m for help): Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): Partition number (1-4, default 1): First sector (2048-41943039, default 2048): Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039): Using default value 41943039 Partition 1 of type Linux and of size 20 GiB is set Command (m for help): The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks.
分别在四个服务器上查看挂载情况
4、设置hosts文件
在第一台node1上修改
#在文件末尾添加 vim /etc/hosts 192.168.45.133 node1 192.168.45.130 node2 192.168.45.134 node3 192.168.45.136 node4
通过scp将hosts文件推送给其他服务器和客户端
#将/etc/hosts文件推送给其他主机 [root@node1 opt]# scp /etc/hosts root@192.168.45.130:/etc/hosts root@192.168.45.130's password: hosts 100% 242 23.6KB/s 00:00 [root@node1 opt]# scp /etc/hosts root@192.168.45.134:/etc/hosts root@192.168.45.134's password: hosts 100% 242 146.0KB/s 00:00 [root@node1 opt]# scp /etc/hosts root@192.168.45.136:/etc/hosts root@192.168.45.136's password: hosts
关闭所有服务器和客户端的防火墙
[root@node1 ~]# systemctl stop firewalld.service [root@node1 ~]# setenforce 0
在客户端和服务器上搭建yum仓库
#进入yum文件路径 [root@node1 ~]# cd /etc/yum.repos.d/ #创建一个空文件夹 [root@node1 yum.repos.d]# mkdir abc #将CentOS-文件全部移到到abc下 [root@node1 yum.repos.d]# mv CentOS-* abc #创建私有yum源 [root@node1 yum.repos.d]# vim GLFS.repo [demo] name=demo baseurl=http://123.56.134.27/demo gpgcheck=0 enable=1 [gfsrepo] name=gfsrepo baseurl=http://123.56.134.27/gfsrepo gpgcheck=0 enable=1 #重新加载yum源 [root@node1 yum.repos.d]# yum list
安装必要软件包
[root@node1 yum.repos.d]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
在其他三台上进行同样的操作
在四台服务器上启动glusterd,并设置为开机自启动
[root@node1 yum.repos.d]# systemctl start glusterd.service [root@node1 yum.repos.d]# systemctl enable glusterd.service
添加节点信息
[root@node1 yum.repos.d]# gluster peer probe node2 peer probe: success. [root@node1 yum.repos.d]# gluster peer probe node3 peer probe: success. [root@node1 yum.repos.d]# gluster peer probe node4 peer probe: success.
在其他服务器上查看节点信息
[root@node1 yum.repos.d]# gluster peer status
创建分布式卷
#创建分布式卷 [root@node1 yum.repos.d]# gluster volume create dis-vol node1:/data/sdb1 node2:/data/sdb1 force #检查信息 [root@node1 yum.repos.d]# gluster volume info dis-vol #查看分布式现有卷 [root@node1 yum.repos.d]# gluster volume list #启动卷 [root@node1 yum.repos.d]# gluster volume start dis-vol
在客户端上挂载
#递归创建挂载点 [root@manager yum.repos.d]# mkdir -p /text/dis #将刚才创建的卷挂载到刚才创建的挂载点下 [root@manager yum.repos.d]# mount.glusterfs node1:dis-vol /text/dis
创建条带卷
#创建卷 [root@node1 yum.repos.d]# gluster volume create stripe-vol stripe 2 node1:/data/sdc1 node2:/data/sdc1 force #查看现有卷 [root@node1 yum.repos.d]# gluster volume list dis-vol stripe-vol #启动条带卷 [root@node1 yum.repos.d]# gluster volume start stripe-vol volume start: stripe-vol: success
在客户端挂载
#创建挂载点 [root@manager yum.repos.d]# mkdir /text/strip #挂载条带卷 [root@manager yum.repos.d]# mount.glusterfs node1:/stripe-vol /text/strip/
创建复制卷
#创建复制卷 [root@node1 yum.repos.d]# gluster volume create rep-vol replica 2 node3:/data/sdb1 node4:/data/sdb1 force volume create: rep-vol: success: please start the volume to access data #开启复制卷 [root@node1 yum.repos.d]# gluster volume start rep-vol volume start: rep-vol: success
在客户机挂碍复制卷
[root@manager yum.repos.d]# mkdir /text/rep [root@manager yum.repos.d]# mount.glusterfs node3:rep-vol /text/rep
创建分布式条带
#创建分布式条带卷 [root@node1 yum.repos.d]# gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force volume create: dis-stripe: success: please start the volume to access data #启动分布式条带卷 [root@node1 yum.repos.d]# gluster volume start dis-stripe volume start: dis-stripe: success
在客户机上挂载
[root@manager yum.repos.d]# mkdir /text/dis-strip [root@manager yum.repos.d]# mount.glusterfs node4:dis-stripe /text/dis-strip/
创建分布式复制卷
#创建分布式复制卷 [root@node2 yum.repos.d]# gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force volume create: dis-rep: success: please start the volume to access data #开启复制卷 [root@node2 yum.repos.d]# gluster volume start dis-rep volume start: dis-rep: success # 查看现有卷 [root@node2 yum.repos.d]# gluster volume list dis-rep dis-stripe dis-vol rep-vol stripe-vol
在客户端挂载
[root@manager yum.repos.d]# mkdir /text/dis-rep [root@manager yum.repos.d]# mount.glusterfs node3:dis-rep /text/dis-rep/
现在我们来进行卷的测试
首先在客户机上创建5个40M的文件
[root@manager yum.repos.d]# dd if=/dev/zero of=/demo1.log bs=1M count=40 40+0 records in 40+0 records out 41943040 bytes (42 MB) copied, 0.0175819 s, 2.4 GB/s [root@manager yum.repos.d]# dd if=/dev/zero of=/demo2.log bs=1M count=40 40+0 records in 40+0 records out 41943040 bytes (42 MB) copied, 0.269746 s, 155 MB/s [root@manager yum.repos.d]# dd if=/dev/zero of=/demo3.log bs=1M count=40 40+0 records in 40+0 records out 41943040 bytes (42 MB) copied, 0.34134 s, 123 MB/s [root@manager yum.repos.d]# dd if=/dev/zero of=/demo4.log bs=1M count=40 40+0 records in 40+0 records out 41943040 bytes (42 MB) copied, 1.55335 s, 27.0 MB/s [root@manager yum.repos.d]# dd if=/dev/zero of=/demo5.log bs=1M count=40 40+0 records in 40+0 records out 41943040 bytes (42 MB) copied, 1.47974 s, 28.3 MB/s
然后复制5个文件到不同的卷上
[root@manager yum.repos.d]# cp /demo* /text/dis [root@manager yum.repos.d]# cp /demo* /text/strip [root@manager yum.repos.d]# cp /demo* /text/rep [root@manager yum.repos.d]# cp /demo* /text/dis-strip [root@manager yum.repos.d]# cp /demo* /text/dis-rep
查看卷的内容
查看分布式卷
查看条带卷
查看复制卷
查看分布式条带卷
查看分布式复制卷
故障测试
关闭node2服务器观察结果
[root@manager yum.repos.d]# ls /text/ dis dis-rep dis-strip rep strip [root@manager yum.repos.d]# ls /text/dis demo1.log demo2.log demo3.log demo4.log [root@manager yum.repos.d]# ls /text/dis-rep demo1.log demo2.log demo3.log demo4.log demo5.log [root@manager yum.repos.d]# ls /text/dis-strip/ demo5.log [root@manager yum.repos.d]# ls /text/rep/ demo1.log demo2.log demo3.log demo4.log demo5.log [root@manager yum.repos.d]# ls /text/strip/ [root@manager yum.repos.d]#
结果表示:
分布卷缺少demo5.log文件 条带卷无法访问 复制卷正常访问 分布式条带卷缺少文件 分布式复制卷正常访问
删除卷
要删除卷需要先停止卷,在删除卷的时候,卷组必须处于开启状态
#停止卷 [root@manager yum.repos.d]# gluster volume delete dis-vol #删除卷 [root@manager yum.repos.d]# gluster volume delete dis-vol
访问控制
#仅拒绝 [root@manager yum.repos.d]# gluster volume set dis-vol auth.reject 192.168.45.133 #仅允许 [root@manager yum.repos.d]# gluster volume set dis-vol auth.allow 192.168.45.133
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论
暂时没有评论,来抢沙发吧~